Une nouvelle recherche menée sur Google Discover
Le 24 février dernier, Metehan Yesilyurt, un consultant SEO turc spécialisé dans la recherche IA, a publié une nouvelle étude sur le fonctionnement de Google Discover, et plus particulièrement sur la manière dont le contenu est évalué, classé ou bloqué par l’outil. En 2025, il avait déjà fait un peu de bruit avec son étude technique menée sur le ranking de Perplexity.
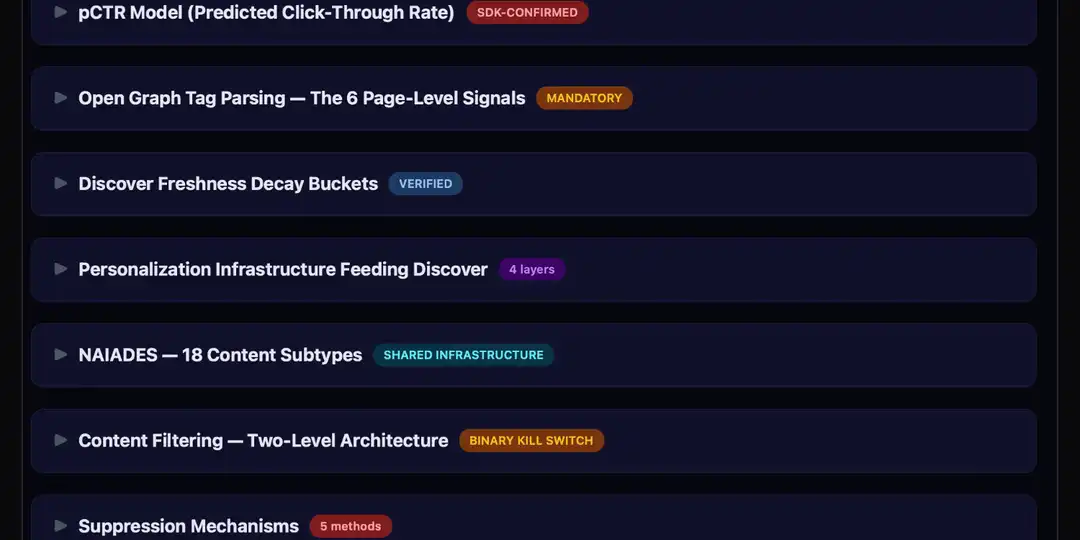
Pour arriver à ces nouveaux résultats, ce professionnel du SEO a analysé le SDK Google (Software Development Kit). Cela lui a notamment permis de reconstituer le pipeline interne de Discover et de découvrir son fonctionnement en 9 étapes.
Pour arriver à ces nouveaux résultats, ce professionnel du SEO a analysé le SDK Google (Software Development Kit). Cela lui a notamment permis de reconstituer le pipeline interne de Discover et de découvrir son fonctionnement en 9 étapes.
Les secrets du fonctionnement de Google Discover révélés ?
Dans un premier temps, il explore et indexe le contenu (Ingestion). Ensuite, il lit les métadonnées Open Graph, comme celles concernant le titre principal, l’image ou encore le nom du site (Parsing OG). À la suite de cela, il classifie le contenu en fonction de deux catégories et 13 clusters. S’agit-il plutôt d’une actualité de dernière minute ou d’un contenu evergreen ? (Classification). Puis, il choisit de bloquer ou non le contenu (Collection Gate).
Après ces quatre premières étapes, c’est le moment de faire correspondre le contenu aux centres d’intérêt de l’utilisateur en s’appuyant sur les Knowledge Graphs (Matching Interests) et de faire un classement. Pour cela, un modèle de prédiction du taux de clics s'exécute côté serveur (pCTR).
En sixième étape, le contenu est organisé selon une hiérarchie très précise : Main-Feed, Collection, Cluster et Card (Assembly). Puis, le contenu est diffusé sur l’appareil de l’utilisateur (Delivery). Enfin, les rejets, abonnements, enregistrements et temps d’engagement des utilisateurs sont étudiés afin d’améliorer la personnalisation du flux Discover en continu (Feedback). Metehan Yesilyurt parle d’ailleurs de “tombstones” pour parler de ces enregistrements persistants côté appareil.
L’avez-vous remarqué ? Un éditeur peut donc se retrouver bloqué avant même que son contenu n’atteigne l’étape du matching et du classement, même si celui-ci s’avère très pertinent pour l’utilisateur.
Fraîcheur du contenu, images, titre : comment travaille Google Discover ?
Que faut-il retenir de cette étude sur le fonctionnement de Google Discover pour améliorer son contenu ? En parcourant cette recherche, nous remarquons tout d’abord que certaines règles concernent les images. En effet, celles-ci doivent absolument être de bonne qualité et rapides à charger, au risque d’être signalées. Leur largeur minimale doit notamment faire 1 200 px.
En parallèle, d’autres signaux de classement peuvent concerner le titre de la page (à optimiser) ou encore la date du contenu. À ce sujet, il faut savoir que la fraîcheur du contenu serait classée selon ces quatre répartitions : 1 à 7 jours (frais), 8 à 14 jours (moyen), 15 à 30 jours (faible), 30 jours et plus (déclin continu). Durant les premières heures, il faut donc envoyer un maximum de signaux positifs vers le contenu en recourant aux réseaux sociaux, à la newsletter ou encore au push.
Autres informations techniques à noter : il existerait 13 clusters internes pour le flux Discover (musntmiss, deeptrends, freshvideos, geotargetingstories, newsstoriesheadlines, etc.) et une personnalisation en quatre couches (Geller / AIP Interest Graph, NAIADES, Persistent State, Engagement Signals), un filtrage en deux niveaux, et plus encore. Découvrez toute l’étendue de l’étude de Metehan Yesilyurt sur son site pour en savoir plus.
Réputation, scoring, matching, feedback… Exploitez toutes les forces de Google Discover pour votre visibilité avec une agence SEO qualifiée sur le sujet. TOP 10 Stratégie peut vous aider pour cela, comme dans bien d’autres domaines (rédaction web, etc.). Contactez-nous !
En parallèle, d’autres signaux de classement peuvent concerner le titre de la page (à optimiser) ou encore la date du contenu. À ce sujet, il faut savoir que la fraîcheur du contenu serait classée selon ces quatre répartitions : 1 à 7 jours (frais), 8 à 14 jours (moyen), 15 à 30 jours (faible), 30 jours et plus (déclin continu). Durant les premières heures, il faut donc envoyer un maximum de signaux positifs vers le contenu en recourant aux réseaux sociaux, à la newsletter ou encore au push.
Autres informations techniques à noter : il existerait 13 clusters internes pour le flux Discover (musntmiss, deeptrends, freshvideos, geotargetingstories, newsstoriesheadlines, etc.) et une personnalisation en quatre couches (Geller / AIP Interest Graph, NAIADES, Persistent State, Engagement Signals), un filtrage en deux niveaux, et plus encore. Découvrez toute l’étendue de l’étude de Metehan Yesilyurt sur son site pour en savoir plus.
Réputation, scoring, matching, feedback… Exploitez toutes les forces de Google Discover pour votre visibilité avec une agence SEO qualifiée sur le sujet. TOP 10 Stratégie peut vous aider pour cela, comme dans bien d’autres domaines (rédaction web, etc.). Contactez-nous !